Professor Calculus is no longer at Marlinspike Hall. (So if you happen to go there and ring for him, all you would be getting would be some Blistering Barnacles.) He's now lecturing full-time at the University of Syldavia. (Of course, he hasn't heard a single complaint from any student or staff member, since he simply doesn't hear them.)
An age-old tradition of the university has been the submission of calculus assignments via FTP. However, things are really about to take a turn, with the recent changes in administrative powers; every lecturer is now required to set up a website where a student can upload her assignment anytime, anywhere; even from her tab or smartphone.
Unfortunately, being a rather conservative person, Prof. Calc has only a very vague idea of what needs to be done (from the very few words that he hardly heard during the faculty meeting).
So, dear reader, it is up to you (and me) to implement a quick solution for Prof. Calc.—before he gets heavily scolded (although inaudibly) during the next staff meeting!
So, before we begin, let's see what challenge lies before us:
- Present the students with a simple website having a file upload form
- Transfer the uploaded file (with the original filename) to the site backend
- Upload the received file into the main FTP server
- Return a response to the frontend indicating whether the upload was successful
- Display the received response to the student
As for the implementation, we have a few choices:
- If we use a traditional stack (such as LAMP we would have to write and maintain code for both the backend and the frontend, probably in different languages.
- We can reduce the overhead by using a unified language like NodeJS, so that the JS-driven frontend will be fairly compatible with the backend (with similar language semantics etc.); still, we'll have to bear the burden of coding the backend (which would be fairly complex relative to the frontend, as it would have to deal with FTP integration). Plus, we'll need a way to reliably host the NodeJS backend, of course.
- Cloud services like Zapier may not be an option because we need the app to be hosted in-house (in-university to be exact), connecting to a local FTP server.
Fortunately, the new Project-X framework has just the right balance for all our requirements:
- Drag-and-drop application composition via UltraStudio, requiring zero lines of code (in most cases)
- A rich palette of connectors (that move data in an out of your integration solution) and processors (that perform units of work on your flowing data) to choose from
- An embedded integration runtime where you can instantly launch and try out your solution, with advanced features like debugging, message flow tracing and content inspection at every stage of the flow
- A wide range of dev and production deployments to choose from—including developer, complete and service-compatible production bundles, Docker and a Kubernetes-, OpenShift- or Amazon ECS-driven, fully-fledged container platform
...and, most impressive for our case... a collection of connectors and processing elements that allows us to build our solution without writing a single line of code!
- A HTTP ingress connector for accepting HTTP traffic (for the web UI and file uploads)
- A Web Server processing element that can serve the frontend (static portion) of the website
- A FTP egress connector that can take all FTP upload matters out of your hand
OK, now that we have the right tool for the job, let's start with the flashy parts—the frontend, that is.
The frontend stuff can be done easily with HTML and JS. To keep things simple (and save time), we shall build a minimal site (without CSS styling, modals and other "complex" goodies.
As for the upload, if we use a regular <form> with an <input type="file">, it would send a multipart upload request to the backend (containing the file name and payload as fields). Multipart uploads are a bit clumsy to handle on the server side, so here we will resort to a custom approach where we send the filename in a HTTP request header named Upload-Filename and the raw file content in the request body.
What follows is a very simple frontend that achieves just what we need (don't worry about the horrific look, we could polish it up later on):
<html>
<head>
<meta charset="utf-8"/>
<title>FilePit Uploader!</title>
</head>
<body>
<form method="post" onsubmit="return runUpload()">
<label for="file">Select the file to upload:</label>
<input type="file" id="file" name="file"/>
<input type="submit" value="Upload"/>
</form>
<script type="text/javascript">
function runUpload() {
var file = document.forms[0].file.files[0];
if (!file) {
alert("Please select a file for uploading :)");
return false;
}
var xhr = new XMLHttpRequest();
xhr.open("POST", "upload");
xhr.setRequestHeader("Upload-Filename", file.name);
xhr.onload = function () {
alert(this.responseText);
};
xhr.onerror = function (e) {
alert("Failed to upload file: " + e);
};
var reader = new FileReader();
reader.onload = function (evt) {
xhr.setRequestHeader("Content-Type", file.type);
xhr.send(evt.target.result);
};
reader.readAsArrayBuffer(file);
return false;
}
</script>
</body>
</html>Now that the frontend is ready, we can download and install UltraStudio and start working on our backend by creating a new project.
One more thing before we begin: when developing the flow, we should better test things using a different FTP server than the actual university server—what if you make a small mistake and all the previously submitted assignments get mixed up, kicking out half the university? You could get hold of a simple FTP server software (e.g. vsftpd for Ubuntu/Debian, FileZilla for Windows, something like this for Mac—unless your Mac is too new), configure it (e.g. in case of vsftpd ensure that you set local_enable=YES and write_enable=YES in /etc/vsftpd.conf—and don't forget to restart the service!), and provide the respective credentials to the coming-up FTP egress connector configuration.
Now, if you're wondering, "okay, how am I supposed to switch to using the actual university server when actually deploying the end solution?", the answer is right here, in our property configuration docs; you'd simply externalize the FTP connector properties—simply by clicking the little toggle buttons to the right of each of its fields that you would be filling—so that you could simply drop a default.properties file (similar to what you would find at src/main/resources of the project) into the final deployment, and things would magically get switched over to the correct FTP server!
Cool, isn't it? (Don't worry, you'll get it later.)
For serving the website, we can get away with a very simple, standard web server flow:
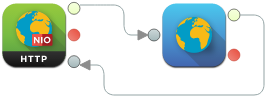
Just drag in a NIO HTTP ingress connector and a Web Server processing element, connect them as in the diagram, and configure them as follows:
HTTP ingress connector:
| Http port | 8280 |
| Service path | /calculus/submissions.* |
Web Server processing element:
| Base Path | /calculus/submissions |
| Base Page | index.html |
Now, create a calculus directory in the src/main/resources path of the project (via the Project side window), create a submissions directory inside it, and save the HTML code that we wrote above inside that directory by the name index.html (so that it will effectively be at src/main/resources/calculus/submissions/index.html). Henceforth, students will see your simple upload page every time they visit /calculus/submissions/ on the "website" that you would soon be hosting—ironically, without any web hosting server or service!
For the upload part, the flow is slightly more complex:

| Http port | 8280 |
| Service path | /calculus/submissions/upload |
Add Variable processor:
| Variable Name | filename |
| Extraction Type | HEADER |
| Value | Upload-Filename |
| Variable Type | String |
Add New Transport Header processor:
| Transport Header Name | ultra.file.name |
| Use Variable | true (enabled) |
| Value | filename |
| Header Variable Type | String |
FTP Egress Connector (make sure to toggle the Externalize Property switch against each property, as described earlier):
| Host | localhost (or external FTP service host/IP) |
| Port | 21 (or external FTP service port) |
| Username | username of FTP account on the server |
| Password | password of FTP account on the server |
| File Path | absolute path on the FTP server to which the file should be uploaded (e.g. /srv/ftp/uploads) |
| File Name | (leave empty) |
String Payload Setter (connected to FTP connector's Response port, i.e. success path):
| String Payload | File successfully uploaded! |
String Payload Setter (connected to FTP connector's On Exception port, i.e. failure path):
| String Payload | Oops, the upload failed :( With error: @{last.exception} |
Response Code Setter (failure path):
| Response Code | 500 |
| Reason Phrase | Internal Server Error |
In English, the above flow does the following (scream it out in the Prof's ear, in case he becomes curious):
- accepts the HTTP file upload request, which includes the file name (
Upload-FilenameHTTP header) and content (payload) - extracts the
Upload-FilenameHTTP header into a scope variable (temporary stage) for future use - assigns the above value back into a different transport header (similar to a HTTP header),
ultra.file.name, that will be used as the name of the file during the FTP upload - sends the received message, whose payload is the uploaded file, into a FTP egress connector, configured for the dear old assigment upload FTP server; here we have left the File Name field of the connector empty, in which case the name would be derived from the abovementioned
ultra.file.nameheader, as desired - if the upload was successful, sets the content of the return message (response) to say so
- if the upload failed due to some reason, sets the response content to include the error and the response code to
500(reasonInternal Server Error); note that the default response code is200(OK) which is why we didn't bother to set it in the success case, and - sends back the updated message as the response of the original upload (HTTP) request
Phew, that's it.
Wasn't as bad as writing a few hundred lines of scary code, was it?
Yup, that's the beauty of composable application development, and of course, of UltraStudio and Project-X!
Now you can test your brand new solution right away, by creating a run configuration (say, calculus) and clicking Run → Run 'calculus'!

(Note that, if it's your first time using UltraStudio, you'll have to add your client key to the UltraStudio configuration before you can run the flow.
Once the run window displays the "started successfully in n seconds" log (within a matter of seconds), simply fire up your browser and visit http://localhost:8280/calculus/submissions/. (Sorry folks, no IE support... Maybe try Edge?)

Oh ho! There's my tiny little upload page!
Just pick a file, and click Upload.
Depending on your stars, you'd either get a "File successfully uploaded!" or "Oops, the upload failed :(" message; hopefully the first :) If not, you may have to switch back to the Run window of the IDE and diagnose what might have gone wrong.
Once you get the successful upload confirmation, just log in to your FTP server, and behold the file that you just uploaded!
That's it!
Now all that is left is to bundle the project into a deployment archive and try it out in the standalone UltraESB-X; which, dear reader, is an exercise left for the reader :)
And, of course, to shout in our Prof's ear, "IT WORKS, PROFESSOR!!!"