Before you begin: aatishnn has a way better implementation here, for HTTP-hosted zipfiles; continue reading if you are interested in knowing the internals, or check out my version if you are interested in checking out files on non-HTTP sources (AWS S3, local/network filesystems, etc.).
Okay, now don't say I'm a zip-worshipper or something :)
But I have seriously been bothered by my lack of control over remote-hosted archive files (zip, tar, jar, whatever); I simply have to download the whole thing, even if I'm interested in just one tiny file—or worse, even when I just want to verify that the file is actually in there, and nothing more.

Google: "view zip content online" (?)
While there's plenty of services that provide ways to check remote zipfile content, it's not as convenient as running a command on my local terminal - plus, more often than not, there are cases where you don't want your content to be exposed to a third party, especially in case of protected storage buckets.
The Odyssey begins
Recently I thought what the heck, and started looking into possible hacks - to view content or partially extract a zipfile without downloading the whole thing.
This SO post lit a spark of hope, and the wiki page set it ablaze.
The central directory
The zip standard defines a central directory (call it CD) that contains an index (listing) of all files in the archive. Each entry contains a pointer (offset) to the (usually compressed) content of the actual file so you can retrieve only the required file(s) without scanning the whole archive.
Problem is, this (obviously) requires random access on the archive file.
And... the central directory is located at the end of the archive, rather than the beginning.
Grabbin' by its tail
Lucky for us, the HTTP Range header comes to the rescue. With it, one can fetch a specific range of bytes of (Range: bytes={start}-{end}) an HTTP entity - just the thing we need, to fetch the last few bytes of the archive.
The header (or rather the concept, when you are at higher levels of abstraction) is supported by other storage providers as well, such as AWS S3. Some web servers may not support it, but most of the popular/standard ones do; so we're mostly covered on that front as well.
But there's another problem. How can we know how big the central directory is; so we can retrieve exactly the right chunk of bytes, rather than blindly scanning for the beginning-of- and end-of-directory records?
And the beauty is: Phil Katz had thought all this through.
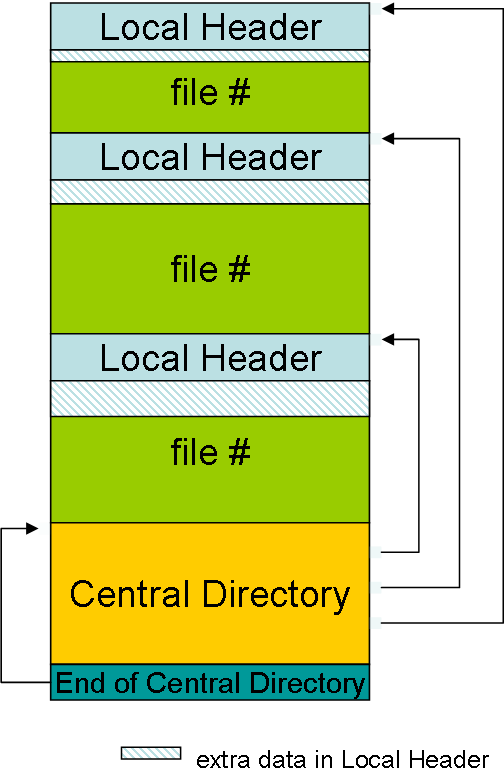
CD, EOCD, WTF?
At the very end of the archive, there's a 22-bit chunk called the end of central directory (I call it EOCD). (Theoretically this could be (22 + n) bytes long, where n is the length of a trailing comment field; but come on, who would bother to add a comment to that obscure, unheard-of thing?) The last few bytes of this chunk contains all you need to know about the central directory!
ls -lR foo.zip/
Our path is now clearly laid out:
- get the total length of the archive via a
HEADrequest (sayL); - fetch the last 22 bits of the file, say, via a ranged
GET(Range: bytes=(L-21)-L); - read bytes 13-16 of the EOCD (in little endian encoding) to find the CD length (say
C); - read bytes 17-20 of the EOCD to find the CD start offset inside the archive (say
O); - do another ranged
GET(Range: bytes=O-(O+C-1)) to fetch the CD; - append the EOCD to the CD, and pray that the resulting blob will be readable as a zip archive!
Guess what, it works!
Zip, you beauty.
The zip format is designed to be highly resilient:
- you can stuff anything at the beginning or middle (before the CD) of the file (which is how self-extracting archives (SFX) work; they have an extractor program (executable chunk) right before the zipfile content);
- you can corrupt the actual content of any file inside the archive, and continue to work with the other uncorrupted entries as if nothing happened (as long as the corruption doesn't affect the size of the content);
- and now, apparently, you can even get rid of the content section entirely!
Everything is fine, as long as the CD and EOCD records are intact.
In fact, even if either (or both) of them is corrupt, the parser program would still be able to read and recover at least part of the content by scanning for the record start signatures.
So, in our case, the EOCD + CD chunk is all we need in order to read the whole zipfile index!
Enough talking, here's the code:
def fetch(file, start, len):
global _key
(bucket, key) = resolve(file)
end = start + len - 1
init(bucket, key)
return _key.get_contents_as_string(headers={"Range": "bytes=%d-%d" % (start, end)})
def head(file):
global _key
(bucket, key) = resolve(file)
init(bucket, key)
return _key.size
def resolve(file):
if file.find("s3://") < 0:
raise ValueError("Provided URL does not point to S3")
return file[5:].split("/", 1)
def init(bucket, key):
global _bucket, _key
if not _bucket:
# OrdinaryCallingFormat prevents certificate errors on bucket names with dots
# https://stackoverflow.com/questions/51604689/read-zip-files-from-amazon-s3-using-boto3-and-python#51605244
_bucket = boto.connect_s3(calling_format=OrdinaryCallingFormat()).get_bucket(bucket)
if not _key:
_key = _bucket.get_key(key)
def parse_int(bytes):
return ord(bytes[0]) + (ord(bytes[1]) << 8) + (ord(bytes[2]) << 16) + (ord(bytes[3]) << 24)
size = head(file)
eocd = fetch(file, size - 22, 22)
cd_start = parse_int(eocd[16:20])
cd_size = parse_int(eocd[12:16])
cd = fetch(file, cd_start, cd_size)
zip = zipfile.ZipFile(io.BytesIO(cd + eocd))(Extract of the full source, with all bells and whistles)
It's in my favorite Python dialect (2.7; though 3.x shouldn't be far-fetched), topped with boto for S3 access and io for wrapping byte chunks for streaming.
What? S3?? I need HTTP!
If you want to operate on a HTTP-served file instead, you can simply replace the first four methods (plus the two "hacky" global variables) with the following:
def fetch(file, start, len):
return requests.get(file, headers={"Range": "bytes=%d-%d" % (start, start + len - 1)}).content
def head(file):
return int(requests.head(file).headers["Content-Length"])A word of gratitude
Lucky for us, Python's zipfile module is as resilient as the standard zip spec, meaning that handles our fabricated zipfile perfectly, no questions asked.
Mission I: accomplished

Mission II
Okay, now that we know what's in the zipfile, we need to see how we can grab the stuff we desire.
The ZipInfo object, which we used earlier for listing the file details, already knows the offset of each file in the archive (as it is - more or less - a parsed version of the central directory entry) in the form of the header_offset attribute.
Negative offset?
However, if you check the raw header_offset value for one of the entries you just got, I bet you'll be confused, at least a lil' bit; because the value is negative!
That's because header_offset is relative to the CD's start position (O); so if you add O to header_offset you simply get the absolute file offset, right away!
Offset of what, sire?
Remember I said, that the above logic gives you the file offset?
Well, I lied.
As you might have guessed, it's the offset of the beginning of another metadata record: the local file header.
Now, now, don't make that long face (my, what a long face!) for the local file header is just a few dozen bytes long, and is immediately followed by the actual file content!
Almost there...
The local file header is a simpler version of a CD file entry, and all we need to know is that it could be (22 + n + m) bytes long; where n is the file name length (which we already know, thanks to the CD entry) and m is the length of an "extra field" (which is usually empty).
The header is structured such that
- name-length (2 bytes),
- extra-field-length (2 bytes),
- name (n bytes), and
- extra-field (m bytes)
appear in sequence, starting at offset 26 on the header. So if we go to the header offset, and step forward by (26 + 2 + 2 + n + m) we'll land right at the beginning of the compressed data!
And... the CD entry (ZipInfo thingy) already gave us the length of the compressed chunk; compress_size!
The Grand Finale
From there onwards, it's just a matter of doing another ranged GET to fetch the compressed content of our file entry of interest, and deflate it if the compress_type flag indicates that it is compressed:
file_head = fetch(file, cd_start + zi.header_offset + 26, 4) name_len = ord(file_head[0]) + (ord(file_head[1]) << 8) extra_len = ord(file_head[2]) + (ord(file_head[3]) << 8) content = fetch(file, cd_start + zi.header_offset + 30 + name_len + extra_len, zi.compress_size) if zi.compress_type == zipfile.ZIP_DEFLATED: print zlib.decompressobj(-15).decompress(content) else: print content

Auditing bandwidth usage
So, in effect, we had to fetch:
- a header-only response for the total length of the file,
- 22 bytes of EOCD,
- the CD, which would usually be well below 1MB even for an archive with thousands of entries,
- 4 + 40-odd bytes of local file header that appears right before the file content (assuming a file name length of 40 bytes), and
- the actual (usually compressed) file entry
instead of one big fat zipfile, most of which we would have discarded afterwards if it was just one file that we were after :)
Even if you consider the HTTP overhead (usually < 1KB per request), we only spent less than 6KB beyond the size of the central directory and the actual compressed payload combined.
Which can, in 90-95% of the cases, be a significant improvement over fetching the whole thing.
In conclusion
Of course, everything I laboriously explained above might mean nothing to you if you actually need the whole zipfile - or a major part of it.
But when you want to
- check if that big fat customer artifact (which you uploaded yesterday, but the local copy was overwritten by a later build; damn it!) has all the necessary files;
- list out the content of a suspicious file that you encountered during a cyberspace hitchhike;
- ensure that you're getting what you're looking for, right before downloading a third-party software package archive (
ZIP,JAR,XPI,WAR,SFX, whatever); - grab that teeny weeny 1KB default configs file from that 4GB game installer (you already have it installed but the configs are somehow fudged up);
you would have a one-liner at hand that would just do it, cheap and fast...
...besides, every geek dev loves a little hackery, don't you?
No comments:
Post a Comment