Yeah, S3 is awesome.
At least till you get the bill.

But it could remain awesome (I mean, for the next month onwards) if you have it by its reins.
Throughout our existence, as AdroitLogic - hosting all our integration software distros, client bundles and temporary customer uploads - as well as SLAppForge - being an integral part of hosting the world's first-ever "serverless" serverless IDE (yeah, you read that right) and being one of its most popular services by developers' choice - we have come across quite a few "oops" and "aha" moments with S3.
And I'll try to head-dump a few, right here.
Okay, what does it bill for?
No point in discussing anything, without a clear idea of that one.

For most use cases, S3 bills you for:
- storage; e.g. $0.03 per a GB-month (each gigabyte retained throughout the last month) in
us-east-1region - data transfer (into and out of the original storage region)
- API calls: listing, writes, reads, etc.
(Well, it's not as simple as that, but those 3 would cover the 80%.)
Glacier is often good enough.
Unless you have read the docs, you might not be aware that S3 was (and is) a key-value store. Meaning that it was designed to provide fast reads as well as writes for frequently-accessed content.
Coincidentally (or perhaps not?), S3's hierarchical storage structure ended up crazily similar to a filesystem, so people (hehe, like ourselves) started using it as file storage - hosting websites, build artifacts, software distributions, and the like.
And backups, of all sorts.
In reality, content like backups are not frequently accessed - in fact never accessed in most cases; and even less frequently (ideally never) updated.
Moving these backups to the low-cost alternative Amazon Glacier could save you a considerable amount of $$. Maybe right from the start, or maybe once they become obsolete (if you cannot make up your mind to delete them).
Once "Glaciered", you can temporarily "promote" or "restore" your stuff back to S3 Standard Storage if you happen to need to access them later; however, don't forget that this restoration itself could take a few hours.
And remember that there's no going back - once a glacier, always a glacier! The only way you could get that thing out of Glacier is by deleting it.
Even so, Glacier is still worth it.
CloudFront
S3 is also a popular choice for hosting static websites (another side effect of that FS-like hierarchy). In such cases, you can reduce the overhead on S3, enhance your site loading speed, and shave off a good portion of your bill, by adding a CloudFront distribution in front.
CloudFront as a CDN has many wheels and knobs that can provide quite a bit of advanced website hosting customizations. It integrates with other origins like EC2, MediaStore/MediaPackage, and third-party HTTP servers as well; and you can get a free AWS-issued SSL cert too, via the AWS Certificate Manager!
![]()
Yuck, that bucket stinks.
S3's role as a filestore often means that you eventually end up with gigabytes of stale content. Stuff that you once needed but no longer do: temporary uploads, old customer bundles, backed-up website content, diagnostics of previous deployments, and the like.
Lifecycle policies: to the rescue!
Luckily, if you know your content good enough (what you need and for how long you need it), you can simply set up a lifecycle policy to delete or archive these content as soon as they become obsolete.
For example,
A policy that would delete all content older than 30 days (from the date of creation) under the path /logs of a bucket, would look like:
{
"Status": "Enabled",
"Expiration": {
"Days": 1
},
"Prefix": "logs"
}Another policy could archive the files that are older than 90 days, under /archived subpath, to Glacier (or RRS - Reduced Redundancy Storage), instead of deleting them:
{
"Status": "Enabled",
"Transitions": [
{
"Days": 90,
"StorageClass": "GLACIER"
}
],
"Prefix": "archived"
}With the latter, for example, you can check your bucket manually and move any "no-longer-used-but-should-not-be-deleted-either" stuff under /archived; and they will be automatically archived after 90 days. If you ever want to reuse something from /archived, just move it outside in order to remove it from the archival schedule.
Free (as in beer) bulk operations!
Lifecycle policies don't cost you anything extra - except for the actual S3 operations, same as when using the API. Just set one up, sit back and relax while S3 does the work for you. Handy when you have a huge bucket or subpath to move or get rid of, but doing it via the S3 console or CLI is going to take ages.
In fact this happened to us once, while we were issuing Free demo AWS keys (yay!) for trying out our serverless IDE Sigma. Some idiot had set up request logging for a certain S3 bucket; and by the time we found out, the destination (logs) bucket had 3+ GB of logs, amounting to millions of records. Any attempt to delete the bucket via the S3 console or CLI would drag on for hours; as S3 requires you to delete every single object before the bucket can be removed. So I just set up a lifecycle config with an empty Prefix, to get rid of everything; free of charge (DELETE API calls are free; thanks Amazon!) and no need to keep my computer running for hours on end!
But wait, there's more to that story...
Watch out! That bucket is versioned!
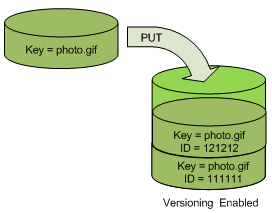
I checked that logs bucket a month later (when I noticed our S3 bill was the same as the last month); and guess what - all that garbage was still sitting there!
Investigating further, we found that our idiot had also enabled versioning for the bucket, so deletion was just an illusion. Under versioning, S3 just puts up a delete marker without really deleting the object content; obviously so that the deleted version can be recovered later. And you keep on getting charged for storage, just like before.
And things just got more complicated!
By now, all log records in that darn bucket had delete markers, so manual deletion was even more difficult; you need to retrieve the version ID for each delete marker and explicitly ask S3 to delete each of them as well!
Luckily, S3 lifecycle rules offer a way to discard expired delete markers - so setting up a new lifecycle config would do the trick (free of charge again):
- discard non-current (deleted) versions of actual objects:
{ "Status": "Enabled", "Prefix": "", "Expiration": { "Days": 1 }, "NoncurrentVersionExpiration": { "NoncurrentDays": 1 } }
- and expire old delete markers:
{ "Status": "Enabled", "Prefix": "", "Expiration": { "ExpiredObjectDeleteMarker": true } }
So remember: if your bucket is versioned, be aware that whatever you do, the original version would be left behind; and only a DeleteObject API call with VersionId can help you get rid of that version - or a lifecycle rule, if there are too many of them.
Checking your buckets without hurting your bill
S3 is quite dumb - no offence meant - in some respects; or am I stepping on AWS's clever and obscure billing tactics?
Unless you're hosting lots and lots of frequently-accessed content - such as customer-facing stuff (software bundles, downloadable documents etc.), your S3 bill will mostly be made of storage charges; as opposed to API calls (reads/writes etc.).
The trick is that, if you try to find the sizes of your S3 buckets, AWS will again charge you for the API calls involved; not to put the blame on them, but it doesn't make much sense - having to spend more in order to assess your spending?

ListBucket: the saviour/culprit
Given that the ListObjects API is limited to 1000 entries per run, this "size-checking" cost can be significant for buckets with several million entries - not uncommon if, for example, you have request logging or CloudTrail trails enabled.
the s3 ls --summarize of aws-cli, the s3cmd command, and even the Get Size operation of the native console, utilize ListObjects in the background; so you run the risk of spending a few cents - maybe even a few dollars - just for checking the size of your bucket.
The GUI has it, so...
The S3 console has a graphical view of the historical sizes of each bucket (volume and object count). This is good enough for manual checks, but not much useful for several dozen buckets, or when you want to automate things.
It comes from CloudWatch!
S3 automatically reports daily stats (BucketSizeBytes and NumberOfObjects) to CloudWatch Metrics, from where you can query them like so:
aws cloudwatch get-metric-statistics \
--namespace AWS/S3 \
--start-time 2019-04-01T00:00:00 \
--end-time 2019-05-01T00:00:00 \
--period 86400 \
--metric-name BucketSizeBytes \
--dimensions Name=StorageType,Value=StandardStorage Name=BucketName,Value={your-bucket-name-here} \
--statistics AverageIn fact the S3 Console also uses CloudWatch Metrics for those fancy graphs; and now, with the raw data in hand, you can do much, much more!
A megabyte-scale usage summary of all your buckets, perhaps?
for bucket in `aws s3api list-buckets --query 'Buckets[*].Name' --output text`; do
size=$(aws cloudwatch get-metric-statistics \
--namespace AWS/S3 \
--start-time $(date -d @$((($(date +%s)-86400))) +%F)T00:00:00 \
--end-time $(date +%F)T00:00:00 \
--period 86400 \
--metric-name BucketSizeBytes --dimensions Name=StorageType,Value=StandardStorage Name=BucketName,Value=$bucket \
--statistics Average \
--output text --query 'Datapoints[0].Average')
if [ $size = "None" ]; then size=0; fi
printf "%8.3f %s\n" $(echo $size/1048576 | bc -l) $bucket
done![]()
Empty buckets don't report anything, hence the special logic for None.
Data transfer counts!
S3 also charges you for actual data transfer out of the original AWS region where the bucket is located.
Host compute on the same zone
If you intend to read from/write to S3 from within AWS (e.g. EC2 or Lambda), try to keep the S3 bucket and the compute instance in the same AWS region. S3 does not charge for data transfers within the same region, so you can save bandwidth costs big time. (This applies to some other AWS services as well.)
Matchmaking with CloudFront
CloudFront is global, and it has to pull updates from S3 periodically. Co-locating your S3 bucket with the CloudFront region where the most client traffic is observed, could reduce cross-region transfer costs; and result in good savings on both ends.
Gzip, and others from the bag of tricks
User-agents (fancy word for browsers and other HTTP clients) accessing your content are usually aware of content encoding. You can gain good savings as well as speedup and performance improvements, by compressing your S3 artifacts (if not already compressed).
When uploading compressed content, remember to specify the Content-Encoding (via the --content-encoding flag) so that the caller will know it is compressed:
aws s3 cp --acl public-read --content-encoding gzip {your-local-file} s3://{your-s3-bucket}/upload/pathIf you're using CloudFront or another CDN in front of S3, it will be able to compress some content for you; however, generally only the well-known ones (.js, .css etc.). A good example is .js.map and .css.map files, commonly found in debug-mode webapps; while CloudFront would compress the .js it would serve the .js.map file uncompressed. By storing the .js.map file compressed on S3 side, storage and transfer overhead will drop dramatically; often by 5-10 times.
In closing
In the end, it all boils down to identifying hot spots in your S3 bill - whether storage, API calls or transfers, and on which buckets. Once you have the facts, you can employ your S3-fu to chop down the bill.
And the results would often be more impressive than you thought.
No comments:
Post a Comment