It all started when the Egyptians slid a few marbles on a wooden frame to ease up on their brains in simple arithmetic; or perhaps when the Greeks invented the Antikythera Mechanism to track the movement of planets to two-degrees-per-millennium accuracy. Either way, computing has come a long way by now: Charles Babbage's Analytical Engine, Alan Turing's Enigma-breaker, NASA's pocket calculator that took man to the moon, Deep Blue defeating Garry Kasparov the Chess Grandmaster, and so forth. In line with this, software application paradigms also have shifted dramatically: from nothing (pure hardware-based programming), monoliths, modularity, SOA, cloud, and now, serverless.
At this point in time, "serverless" generally means FaaS (functions-as-a-service); and FaaS literally means AWS Lambda, both from popularity and adoption points of view. Hence it is not an exaggeration to claim that the popularity of serverless development would be proportional to the ease of use of lambdas.
Well, lambda has been there since 2015, is already integrated into much of the AWS ecosystem, and is in production use at hundreds (if not thousands) of companies; so lambda should be pretty intuitive and easy to use, right?
Well, it seems not, at least in my case. And my "case" being one of the official AWS examples, I'm not quite convinced whether lambda is friendly enough for newbies to the picture.
For a start, I wanted to implement AWS's own thumbnail creation use case without following their own guide, to see how far I could get.
As a programmer, I naturally started with the Lambda management console. The code had already been written by generous AWS guys, so why reinvent the wheel? Copy, paste, save, run. Ta da!
Hmm, looks like I need to grow up a bit.
The "Create function" wizard was quite eye-catching, to be frank. With so many ready-made blueprints. Too bad it didn't already have the S3 thumbnail generation sample, or this story could have ended right here!
So I just went ahead with the "Author from scratch" option, with a nice name s3-thumbnail-generator.
Oh wait, what's this "Role" thing? It's required, too. Luckily it has a "Create new role from template(s)" option, which would save my day. (I didn't have any options under "Choose an existing role", and I'm too young to "Create a custom role".)
Take it easy. "Role name": s3-thumbnail-generator-role. But how about the "policy template"?
Perhaps I should find something S3-related, since my lambda is all-S3.
Surprise! The only thing I get when I search for S3, is "S3 object read-only permissions". Having no other option I just snatched it. Let's see how far I can get before I fall flat on my face!
Time to hit "Create function".

Wow, their lambda designer looks really cool!

"Congratulations! Your Lambda function "s3-thumbnail-generator" has been successfully created. You can now change its code and configuration. Click on the "Test" button to input a test event when you are ready to test your function."
Okay, time for my copy-paste mission. "Copy" on the sample source code, Ctrl+A and Ctrl+V on the lambda code editor. Simple!
All green (no reds). Good to know.
"Save", and "Test".

Oh, I should have known better. Yup, if I am going to "test", I need a "test input". Obviously.
I knew that testing my brand-new lambda would not be as easy as that, but I didn't quite expect having to put together a JSON-serialized event by hand. Thankfully the guys had done a great job here as well, providing a ready-made "S3 Put" event template. So what else would I select? :)

As expected, the first run was a failure:
{
"errorMessage": "Cannot find module 'async'",
"errorType": "Error",
"stackTrace": [
"Function.Module._load (module.js:417:25)",
"Module.require (module.js:497:17)",
"require (internal/module.js:20:19)",
"Object. (/var/task/index.js:2:13)",
"Module._compile (module.js:570:32)",
"Object.Module._extensions..js (module.js:579:10)",
"Module.load (module.js:487:32)",
"tryModuleLoad (module.js:446:12)",
"Function.Module._load (module.js:438:3)"
]
} Damn, I should have noticed those require lines. And either way it's my bad, because the page where I copied the sample code had a big fat title "Create a Lambda Deployment Package", and clearly explained how to bundle the sample into a lambda-deployable zip.
So I created a local directory containing my code, and the package.json, and ran an npm install (good thing I had node and npm preinstalled!). Building, zipping and uploading the application was fairly easy, and hopefully I would not have to go through a zillion and one such cycles to get my lambda working.
(BTW, I wish I could do this in their built-in editor itself; too bad I could not figure out a way to add the dependencies.)
Anyway, time is ripe for my second test.
{
"errorMessage": "Cannot find module '/var/task/index'",
"errorType": "Error",
"stackTrace": [
"Function.Module._load (module.js:417:25)",
"Module.require (module.js:497:17)",
"require (internal/module.js:20:19)"
]
}index? Where did that come from?
Wait... my bad, my bad.

Seems like the Handler parameter still holds the default value index.handler. In my case it should be CreateThumbnail.handler (filename.method).
Let's give it another try.

Seriously? No way!
Ah, yes. The logs don't lie.
2018-02-04T17:00:37.060Z ea9f8010-09cc-11e8-b91c-53f9f669b596 Unable to resize sourcebucket/HappyFace.jpg and upload to sourcebucketresized/resized-HappyFace.jpg due to an error: AccessDenied: Access Denied END RequestId: ea9f8010-09cc-11e8-b91c-53f9f669b596
Fair enough; I don't have sourcebucket or sourcebucketresized, but probably someone else does. Hence the access denial. Makes sense.
So I created my own buckets, s3-thumb-input and s3-thumb-inputresized, edited my event input (thanks to the "Configure test event" drop-down) and tried again.
2018-02-04T17:06:26.698Z bbf940c2-09cd-11e8-b0c7-f750301eb569 Unable to resize s3-thumb-input/HappyFace.jpg and upload to s3-thumb-inputresized/resized-HappyFace.jpg due to an error: AccessDenied: Access Denied
Access Denied? Again?
Luckily, based on the event input, I figured out that the 403 was actually indicating a 404 (not found) error, since my bucket did not really contain a HappyFace.jpg file.
Hold on, dear reader, while I rush to the S3 console and upload my happy face into my new bucket. Just a minute!
Okay, ready for the next test round.
2018-02-04T17:12:53.028Z a2420a1c-09ce-11e8-9506-d10b864e6462 Unable to resize s3-thumb-input/HappyFace.jpg and upload to s3-thumb-inputresized/resized-HappyFace.jpg due to an error: AccessDenied: Access Denied
The exact same error? Again? Come on!
It didn't make sense to me; why on Earth would my own lambda running in my own AWS account, not have access to my own S3 bucket?
Wait, could this be related to that execution role thing; where I blindly assigned S3 read-only permissions?
A bit of Googling led me to the extremely comprehensive AWS IAM docs for lambda, where I learned that the lambda executes under its own IAM role; and that I have to manually configure the role based on what AWS services I would be using. Worse still, in order to configure the role, I have to go all the way to the IAM management console (which—fortunately—is already linked from the execution role drop-down and—more importantly—opens in a new tab).

Fingers crossed, till the custom role page loads.
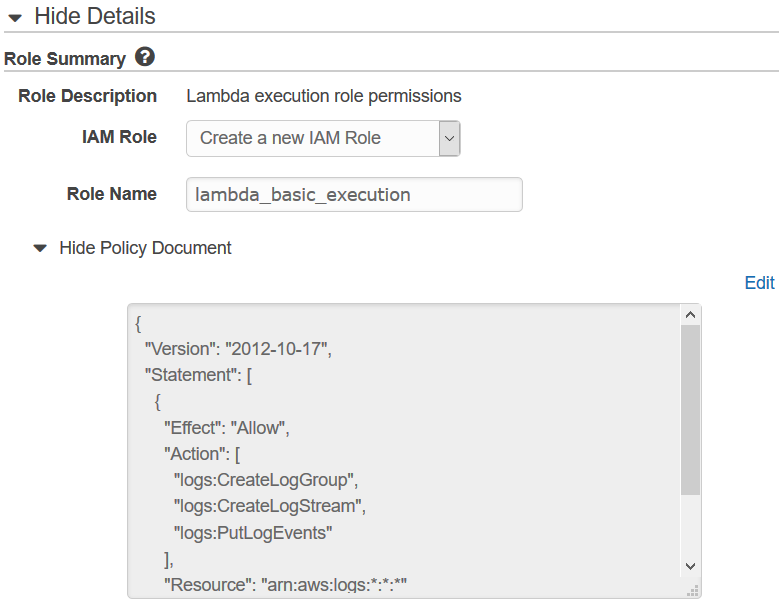
Oh no... More JSON editing?
In the original guide, AWS guys seemed to have nailed the execution role part as well, but it was strange that there was no mention of S3 in there (except in the name). Did they miss something?
Okay, for the first time in history, I am going to create my own IAM role!
Bless those AWS engineers, a quick Googling revealed their policy generator jewel. Just the thing I need.
But getting rid of the JSON syntax solves only a little part of the problem; how can I know which permissions I need?
Google, buddy? Anything?
Ohh... Back into the AWS docs? Great...
Well, it wasn't that bad, thanks to the S3 permissions guide. Although it was somewhat overwhelming, I guessed what I needed was some permissions for "object operations", and luckily the doc had a nice table suggesting that I needed s3:GetObject and s3:PutObject (consistent with the s3.getObject(...) and s3.putObject(...) calls in the code).

After some thinking, I ended up with an "IAM Policy" with the above permissions, on my bucket (named with the tedious syntax arn:aws:s3:::s3-thumb-input):
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1517766308321",
"Action": [
"s3:PutObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::s3-thumb-inputresized"
},
{
"Sid": "Stmt1517766328849",
"Action": [
"s3:GetObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::s3-thumb-input"
}
]
}And pasted and saved it on the IAM role editor (which automatically took me back to the lambda console page; how nice!)
Try again:
Same error?!
Looking back at the S3 permissions doc, I noticed that the object permissions seem to involve an asterisk (/* suffix, probably indicating the files) under the resource name. So let's try that as well, with a new custom policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1517766308321",
"Action": [
"s3:PutObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::s3-thumb-inputresized/*"
},
{
"Sid": "Stmt1517766328849",
"Action": [
"s3:GetObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::s3-thumb-input/*"
}
]
}Again (this is starting to feel like Whiplash):
2018-02-04T17:53:45.484Z 57ce3a71-09d4-11e8-a2c5-a30ce229e8b7 Successfully resized s3-thumb-input/HappyFace.jpg and uploaded to s3-thumb-inputresized/resized-HappyFace.jpg
WOO-HOO!!!
And, believe it or not, a resized-HappyFace.jpg file had just appeared in my s3-thumb-inputresized bucket; Yeah!
Now, how can I configure my lambda to automatically run when I drop a file into my bucket?
Thankfully, the lambda console (with its intuitive "trigger-function-permissions" layout) made it crystal clear that what I wanted was an S3 trigger. So I added one, with "Object Created (All)" as the "Event Type" and "jpg" as the suffix, saved everything, and dropped a JPG file into my bucket right away.

Yup, works like a charm.
To see how long the whole process took (in actual execution, as opposed to the "tests"), I clicked the "logs" link on the (previous) execution result pane, and went into the newest "log stream" shown there; nothing!
And more suspiciously, the last log in the newest log stream was an "access denied" log, although I had gotten past that point and even achieved a successful resize. Maybe my latest change broke the logging ability of the lambda?
Thanks to Google and StackOverflow, I found that my execution role needs to contain some logging related permissions as well; indeed, now I remember there were some permissions in the permission editor text box when I started creating my custom role, and once again I was ignorant enough to paste my S3 policies right over them.
Another round of policy editing:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1517766308321",
"Action": [
"s3:PutObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::s3-thumb-inputresized/*"
},
{
"Sid": "Stmt1517766328849",
"Action": [
"s3:GetObject"
],
"Effect": "Allow",
"Resource": "arn:aws:s3:::s3-thumb-input/*"
},
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Effect": "Allow",
"Resource": "arn:aws:logs:*:*:*"
}
]
}Another file drop, and this time both the resize and the logs worked flawlessly... Finally!
Now that everything is straightened out, and my thumbnail is waiting in my destination bucket, I fired up my browser, typed http://s3-thumb-inputresized.s3.amazonaws.com/resized-HappyFace.jpg (in accordance with the S3 virtual hosting docs), and hit Enter, expecting a nice thumbnail in return.
<Error> <Code>AccessDenied</Code> <Message>Access Denied</Message> <RequestId>C8BAC3D4EADFF577</RequestId> <HostId>PRnGbZ2olpLi2eJ5cYCy0Wqliqq5j1OHGYvj/HPmWqnBBWn5EMrfwSIrf2Y1LGfDT/7fgRjl5Io=</HostId> </Error>
Already tired of that "AccessDenied" message!
Apparently, although my code generates the file, it does not make the file publicly accessible (but what good would a private thumbnail be, huh?)
Digging through the AWS docs, I soon discovered the ACL parameter of the putObject operation, which allows the S3 uploaded file to be public. Hoping this would solve all problems on the planet, I quickly upgraded my code to set the file's ACL to public-read:
s3.putObject({
Bucket: dstBucket,
Key: dstKey,
Body: data,
ContentType: contentType,
ACL: 'public-read'
},
next);
}Saved the function, and hit Test:
2018-02-04T18:06:40.271Z 12e44f61-19fe-11e8-92e1-3f4fff4227fa Unable to resize s3-thumb-input/HappyFace.jpg and upload to s3-thumb-inputresized/resized-HappyFace.jpg due to an error: AccessDenied: Access Denied
Again?? Are you kidding me?!
Fortunately, this time I knew enough to go straight into the S3 permissions guide, which promptly revealed that I also needed to have the s3:PutObjectAcl permission in my policy, in order to use the ACL parameter in my putObject call. So another round trip to the policy editor, to the IAM dashboard, and back to the lambda console.
2018-02-04T18:15:09.670Z 1d8dd7b0-19ff-11e8-afc0-138b93af2c40 Successfully resized s3-thumb-input/HappyFace.jpg and uploaded to s3-thumb-inputresized/resized-HappyFace.jpg
And this time, to my great satisfaction, the browser happily showed me my happy face thumbnail when I fed the hosting URL http://s3-thumb-inputresized.s3.amazonaws.com/resized-HappyFace.jpg into it.
All in all, I'm satisfied that I was finally able to solve the puzzle on my own, by putting all the scattered pieces together. But I cannot help imagining how cool it would have been if I could build my lambda in freestyle, with AWS taking care of the roles, permissions and whatnot, on its own, without getting me to run around the block.
Maybe I should have followed that official guide, right from the start... but, then again, naaah :)