I usually keep an eye on various websites - for latest publications, hot new offers, limited-time games and contests, and the like.
Most of these do not offer a "clean" notification system, such as an RSS feed. So I often have to scrape their HTML to get to what I need.
Which means I often need to run some custom string manipulation magic to get to what I need.
And I need it to be periodic (who knows when the next hot update would surface?).
And automatic (I have more important things to do during my day).
And remotely hosted (I don't want to keep my laptop running 24×7, with an uninterrupted internet connection).
So far I have been relying on Google Apps Script (and more recently, Google App Engine) for driving these sorts of home-made integration "snippets"; however, with the whole world immersing itself in serverless, why shouldn't I?
So I set out to migrate one of my scripts, written for monitoring a Chinese retail website. The site occasionally publishes various discounted offers and seasonal games where I can earn nice coupons and credits via daily plays. But for some reason the site does not send out promotional emails to my email address, which means I have to keep checking the site every once in a while just to make sure that I won't miss something cool.
And you know the drill.
I forget things easily. Sometimes, when I'm away from my computer, I miss the reminder as well. Sometimes I'm just too lazy to look things up, because I end up with nothing new, 75-80% of the time. So many excuses...
Besides, who in their right developer mind wants to do something as boring as that, when you can just set up a bot, sit back, and relax?!
I started off with AWS Lambda, the obvious choice for free serverless computing. Its non-expiring free tier gives me an unbelievable 3.2M (yes, million) seconds of runtime per month - I can virtually keep one lambda running forever, and a little bit more! - across 1M (million again!) invocations. Previously on Apps Script or App Engine I had just 90 minutes per day - a little over 160K seconds per month - meaning that I had to use my quotas very sparingly; but now I can let go of my fears and fully enjoy my freedom of development. Not to mention the fully-fledged container environment in contrast to the framework confinements of Apps Script or App Engine.
Enough talk. Let's code!
Rather than taking the standard path, I picked Sigma from SLAppForge as my development framework; primarily because it had some reputation for supporting external dependencies, and taking care of packaging and deploying stuff on my behalf - including all the external services (APIs, tables, crons and whatnot).
First I had to sign up for Sigma. Although I could have gone ahead with their demo feature (the big yellow button), I already had an AWS account and a GitHub account (not to mention an email address); so why not give it a shot?

When completed the registration and logged in, I was greeted with a project selection pane, where I opted for a new project with name site-monitor:

The app was blazingly fast, and the editor popped up as soon as I hit Create Project:

Without further ado, I grabbed the content of my former Apps Script function and dropped it into Sigma!
let AWS = require('aws-sdk');
exports.handler = function(event, context, callback) {
// Here Goes Nothing
PROPS = PropertiesService.getScriptProperties();
page = UrlFetchApp.fetch("http://www.my-favorite-site.com").getResponseText();
url = page.match(/(lp|\?r=specialTopic)\/[^"]*/)[0];
if (url != PROPS.getProperty("latest")) {
GmailApp.sendEmail("janakaud@gmail.com", "MyFavSite Update!", url);
PROPS.setProperty("latest", url);
}
// end of Here Goes Nothing
callback(null,'Successfully executed');
}(I know, I know, that didn't work. Bear with me :))
The next several minutes, I spent transforming my Apps Script code into NodeJS. It was not that hard (both are JS, after all!) once I got the request module added to my project:


But I must say I did miss the familiar, synchronous syntax of the UrlFetchApp module.
Under App Engine I had the wonderfully simple PropertiesService to serve as the "memory" of my bot. Under Sigma (AWS) things were not that simple; after some look-around I decided to go with DynamoDB (although I still felt it was way much overkill).
Once I have extracted the URL from the page, I needed to check if I have already notified myself of it; the equivalent of querying my table (formerly the PropertiesService) for an existing entry. In DynamoDB-land this was apparently a Get Document operation, so I tried dragging in DynamoDB into my code:

Once dropped, the DynamoDB entry transformed into a pop-up where I could define my table and provide the code-level parameters as well. Hopefully Sigma would remember the table configuration so I won't have to enter it again and again, all over my code.

Since DynamoDB isn't a simple key-value thingy, I spent a few minutes scratching my head on how to store my "value" in there; eventually I decided to use a "document" structure of the form
{
"domain": "my-favorite-site.com",
"url": "{the stored URL value}"
}where I could query the table using a specific domain value for each bot, and hence reuse the table for different bots.
In my old code I had used a GmailApp.sendEmail() call to send myself a notification when I got something new. In Sigma I tried to do the same by dragging and dropping a Simple Email Service (SES) entry:

Here there was a small hiccup, as it appeared that I would need to verify an email address before I could send something out. I wasn't sure how bumpy my ride would be, anyway I entered my email address and clicked Send verification email.
Sure enough, I received a verification link via email which, when clicked, redirected me to a "Verification successful" page.
And guess what: when I switched back to Sigma, the popup had updated itself, stating that the email was verified, and guiding me through the next steps!
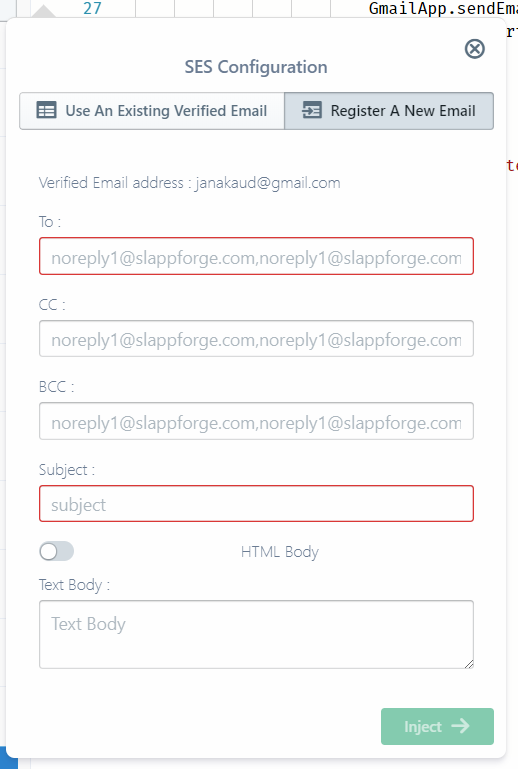
I filled in the details right away (To myself, no CC's or BCC's, Subject MyFavSite Update! and Text Body @{url} (their own variable syntax; I wish it were ${} though)):

In the callback of SES email sender, I had to update the DynamoDB table to reflect the new entry that was emailed out (so I won't email it again). Just like the PROPS.setProperty("latest", url) call in my original bot.
That was easy, with the same drag-n-drop thingy: selecting the previously created table under Existing Tables and selecting a Put Document operation with domain set to my-favorite-site.com (my "search query"; equivalent of "latest" in the old bot) and a url entry set to the emailed URL:

Eventually I ended up with a fairly good piece of code (although it was way longer than my dear old Apps Script bot):
let AWS = require('aws-sdk');
const ses = new AWS.SES();
const ddb = new AWS.DynamoDB.DocumentClient();
const request = require("request");
exports.handler = function (event, context, callback) {
request.get("http://www.my-favorite-site.com",
(error, response, body) => {
if (!body) {
throw new Error("Failed to fetch homepage!");
}
let urls = page.match(/(lp|\?r=specialTopic)\/[^"]*/);
if (!urls) { // nothing found; no point in proceeding
return;
}
let url = urls[0];
ddb.get({
TableName: 'site-data',
Key: { 'domain': 'my-favorite-site.com' }
}, function (err, data) {
if (err) {
throw err;
} else {
if (!data.Item || data.Item.url != url) {
ses.sendEmail({
Destination: {
ToAddresses: ['janakaud@gmail.com'],
CcAddresses: [],
BccAddresses: []
},
Message: {
Body: {
Text: {
Data: url
}
},
Subject: {
Data: 'MyFavSite Update!'
}
},
Source: 'janakaud@gmail.com',
}, function (err, data) {
if (err) {
throw err;
}
ddb.put({
TableName: 'site-data',
Item: { 'domain': 'my-favorite-site.com', 'url': url }
}, function (err, data) {
if (err) {
throw err;
} else {
console.log("New URL saved successfully!");
}
});
});
} else {
console.log("URL already sent out; ignoring");
}
}
});
});
callback(null, 'Successfully executed');
}Sigma was trying to help me all the way, by providing handy editing assistance (code completion, syntax coloring, variable suggestions...), and even highlighting the DynamoDB and SES operations and displaying tiny icons in front; which, when clicked, displayed (re)configuration pop-ups similar to what I got when I drag-dropped them the first time.
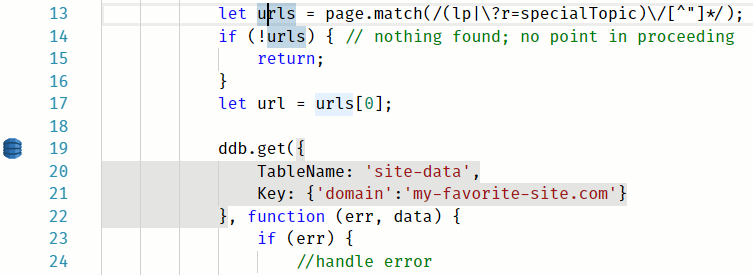

Due to the async, callback-based syntax, I had to move around bits 'n' pieces of my code several times. Sigma handled it pretty well, re-doing the highlighting stuff a second or two after I pasted the code in its new location.
Just for fun, I tried editing the code manually (without using the pop-up) and, fair enough, the pop-up understood the change and updated itself the next time I checked. Pretty neat for a newbie who wants to get stuff done without diving into the docs.
Now, how can I run my bot periodically?
Sigma shows a red lightning sign near the function header, and highlights the event parameter in the same. Possibly indicating it's the point of invocation or triggering of the lambda.

Yup. Their docs say the same.
AWS docs and Sigma's own ones pointed me to CloudWatch scheduled event triggers that could trigger a lambda with a predefined schedule - like Apps Script triggers but much more powerful; more like App Engine cron expressions.
As mentioned in their docs, I dragged a CloudWatch entry on to the event variable and configured it like so:

And the whole event thing changed from red to green, possibly indicating that my trigger was set up successfully.
Right. Time to test it out.
The toolbar has a Test (play) button, with a drop-down to select your test case. Like Apps Script, but much better in the sense that you can defne the input payload for the invocation (whereas Apps Script just runs the function without any input arguments):


As soon as I configured a test case and hit the run button, the status bar started showing a running progress:

Few seconds later, a SigmaTrail log output window automagically popped up, and started showing some logs:

errorMessage:"RequestId: 87c59aba-8822-11e8-b912-0f46b6510aa8 Process exited before completing request" [7/15/2018][5:00:52 PM] Updating dependencies. This might make runtime longer than usual. [7/15/2018][5:00:55 PM] Dependencies updated. [7/15/2018][5:00:57 PM] ReferenceError: page is not defined at Request.request.get [as _callback] (/tmp/site-monitor/lambda.js:13:24) at Request.self.callback (/tmp/site-monitor/node_modules/request/request.js:185:22)
Oops, looks like I got a variable name wrong.
A simple edit, and another test.
[7/15/2018][5:04:50 PM] ResourceNotFoundException: Requested resource not found at Request.extractError (/tmp/site-monitor/node_modules/aws-sdk/lib/protocol/json.js:48:27) at Request.callListeners (/tmp/site-monitor/node_modules/aws-sdk/lib/sequential_executor.js:105:20)
Hmm, what does that mean?
Looks like this one's coming from the AWS SDK itself.
Maybe the AWS "resources" I dragged-n-dropped into my app are not yet available on AWS side; besides, many of the Sigma tutorials mention a "deployment" step before they go into testing.
Oh well, let's try deploying this thing.

I was hoping a seamless "one-click deploy", but when I clicked the Deploy button I just got a pop-up saying I need to authenticate to GitHub. Sigma might probably be saving my stuff in a GitHub repo and then using it for the rest of the deployment.

Seeing no evil, I clicked the sign-in, and authorized their app on the pop-up window that followed. Within a few seconds, I got another pop-up asking me to pick a repo name and a commit message.

I didn't have a repo site-monitor in my account, so I was curious to see what Sigma would do. Just as I suspected, after a few seconds from clicking Commit, another dialog popped-up asking whether I would like it to create a new repo on my behalf.

Sigma was so kind that it even offered to create a private repository; but alas, I didn't have the luxury, so I just clicked Create Repo and Commit.
From there onwards, things were fairly automated: after the "Successfully commmitted" notification, there was a lightningly fast "build" step (accompanied by a progress bar in the bottom status pane).
Next I got another pop-up, this time a Changes Summary; which, after a few more seconds, populated itself with a kind of "deployment summary":

I wasn't much interested in the low-level detail (though I did recognize the cweOneAM as my cron trigger and siteMonitorLambda as my bot), so I just hit Execute; and this time there was a fairly long wait (accompanied by another progress bar, this time within the pop-up itself).

Once it hit the 100% mark, Sigma stated that my deployment completed with a CREATE_COMPLETE state (sounds good!).
Now let's try that testing thing, again.
"Successfully executed" [7/15/2018][5:39:34 PM] New URL saved successfully!

Yay!
Wait, will it resend if I run it again?
"Successfully executed" [7/15/2018][5:39:41 PM] URL already sent out; ignoring
All good; no duplicates!
Now to check my inbox, to see if Sigma is telling the truth.
Initially I was a bit confused because I didn't actually receive an email; but eventually I found it sitting in my Spam folder (probably because it was sent by a third party (AWS)?), and unmarking it as spam did the trick.

Hopefully my CloudWatch trigger would fire tomorrow at 1 AM, bringing me the good news if there are any!
All in all, the graphical IDE is quite slick and recommendable to my colleagues. Except for the deployment time (which I guess is characteristic to serverless apps, or Lambda, or perhaps AWS), I felt almost at home - and even more so, with all the nifty features - autocompletion, drag-n-drop, GUI configs, testing, logs, and so forth.
Time for a cuppa coffee, and then to start migrating my other bots to Sigma... um... AWS.